Sagas e Compensações: orquestração por eventos sem drama
Quando um processo atravessa múltiplos sistemas, transações distribuídas são inevitáveis. Em vez de bloquear tudo com mecanismos clássicos (2PC, rollback global), usamos sagas — uma sequência de passos com compensações bem definidas, modeladas em BPMN e controladas por eventos. O objetivo é simples: manter a consistência de negócio sem sacrificar escalabilidade, resiliência e independência de serviços.
Porquê usar sagas
- Evitam bloqueios e gargalos em transações longas. Em vez de uma transação única e extensa, cada passo confirma localmente; se algo falha, compensamos os passos anteriores.
- Resilientes a falhas parciais. Um serviço pode falhar, a rede pode oscilar — o processo continua ou repara quando voltar, graças a reentregas e compensações.
- Reprocessamento controlado e auditável. Estados de saga ficam registados; é possível retomar, reexecutar ou encerrar com segurança.
- Orquestração simples em arquiteturas event-driven e micro-serviços. Os serviços comunicam via eventos, e o core de negócio fica desenhado de forma explícita.
Orquestração vs. Coreografia
Orquestração: existe um “maestro” da saga (um orquestrador) que decide o próximo passo, publica comandos e recolhe eventos. Em BPMN, pense num processo principal que invoca tarefas de serviço e reage a eventos.
Coreografia: não há maestro central; cada serviço reage a eventos e emite os seus. Isto reduz acoplamento, mas torna o fluxo menos visível. Muitas equipas começam por coreografia e, à medida que as compensações ficam complexas, migram para orquestração ou modelos híbridos.
Regra prática: quando as dependências e compensações são não triviais, prefira orquestração. Use coreografia para passos simples e independentes.
Como modelar uma saga em BPMN
- Processo principal com Service Tasks que invocam sistemas externos via mensagem/comando.
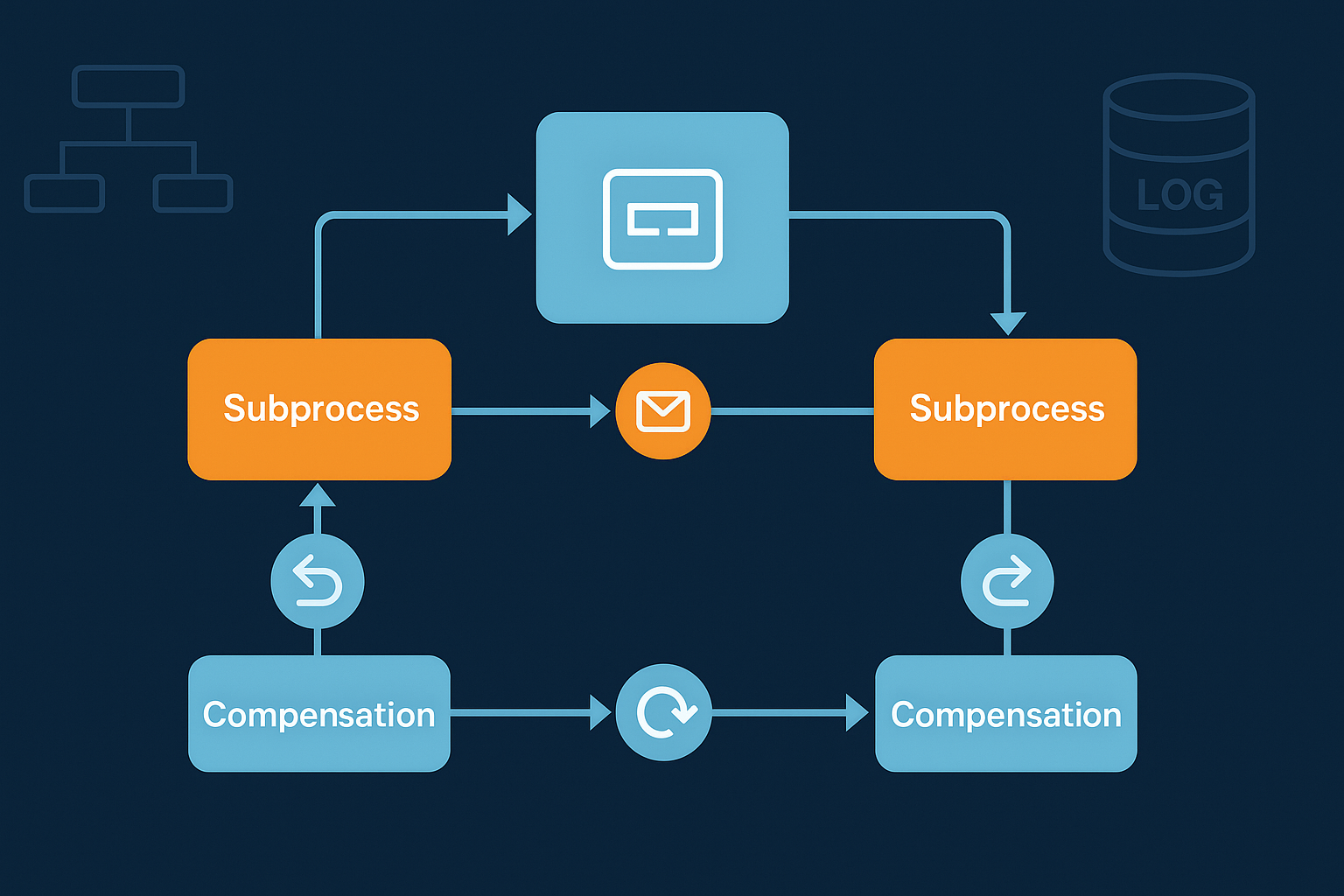
- Subprocessos transacionais (Transaction) quando fizer sentido agrupar passos com semântica de “tudo ou nada” local.
- Eventos de compensação: para cada tarefa que altera estado externo (reservar stock, debitar cartão), adicione uma tarefa de compensação (cancelar reserva, estornar pagamento).
- Boundary events:
- Error para falhas imediatas e irrecuperáveis.
- Timer (Timeout/SLA) para detetar atrasos e acionar compensação.
- Escalation para acionar suporte humano quando necessário.
- Event Subprocess para lidar com cancelamentos globais (ex.: cliente cancela a encomenda) ou incidentes transversais.
Exemplo simplificado (e-commerce)
Passos de ida:
- Validar pedido
- Reservar stock
- Autorizar pagamento
- Criar encomenda e emitir fatura
- Solicitar expedição
Compensações:
- Se expedição falhar: cancelar expedição (se aplicável).
- Se faturação falhar: estornar pagamento e libertar stock.
- Se pagamento falhar: libertar stock.
- Se reserva falhar: notificar cliente e encerrar como “sem stock”.
Em BPMN, cada Service Task tem associada uma tarefa de compensação; os timer boundary events garantem que tempos de resposta excessivos disparam rotas alternativas.
Decisões com DMN
Ao longo de uma saga, surgem decisões condicionais: “devo compensar agora ou aguardar?”, “qual o tipo de compensação?”, “quantas tentativas de reentrega?”. Modelar estas decisões em DMN (Decision Model and Notation) separa regras de negócio do fluxo.
Exemplos de decisões em DMN:
- Política de retries: por tipo de erro (transiente vs. permanente), define número de tentativas e backoff.
- Ramo de compensação: se o stock é perecível ou reservado em marketplace externo, a compensação pode ser parcial ou exigir confirmação humana.
- SLA: prazos por categoria de cliente (premium vs. standard) para acionar escaladas.
Benefícios: transparência para negócio; testabilidade independente do fluxo; facilidade de alterar regras sem mexer no processo.
Estado e rastreabilidade da saga
- Log de eventos (event store) ou broker (Kafka, RabbitMQ, etc.) como fonte de verdade do que aconteceu.
- Correlation IDs: cada saga tem um identificador único que acompanha todos os eventos e logs.
- Outbox pattern: grava mutações de estado e mensagens de saída na mesma transação local do serviço, para evitar “perda” de mensagens.
- Auditabilidade: snapshots do estado da saga + trilha de eventos permitem reconstrução e análise forense.
Idempotência e reentrega
- Operações idempotentes: aplicar duas vezes tem o mesmo efeito que uma.
- Chaves de deduplicação (ex.:
operationId) persistidas. - Side effects controlados: nunca executar compensação duas vezes — marcar compensações aplicadas.
Timeouts, SLAs e monitorização
“Arquitetura de eventos sem drama” exige observabilidade:
- Timeouts: configure timers por etapa (ex.: pagamento deve responder em 15s; expedição em 2h).
- SLAs: nivelados por produto/cliente; use DMN para mapear prazos.
- Métricas: taxa de sucesso, tempo médio de saga (lead time), número de compensações por tipo, incidentes por etapa.
- Alertas proativos: percentis (p95/p99) a estourar, filas a crescer, taxa de DLQ acima do normal.
Padrões de resiliência
- Retry com exponential backoff e jitter para erros transitórios.
- Circuit breaker para isolar serviços instáveis.
- Timeouts curtos + fallback (ex.: reserva provisória, confirmação posterior).
- Bulkhead: isolar pools de threads/conexões para evitar efeito dominó.
- Dead Letter Queue (DLQ) com fluxo de reprocessamento manual ou automatizado.
Testes de sagas
- Unitários de decisão (DMN): validar regras independentemente.
- Contratos de mensagens (schema/Avro/JSON): prevenir quebras entre produtores e consumidores.
- Testes orquestrados ponta-a-ponta: simular falhas em passos específicos e garantir compensações corretas.
- Chaos engineering: injetar latência e falhas para medir comportamento e tempos de compensação.
Anti-padrões a evitar
- Compensações implícitas ou “depois vê-se”. Tudo o que altera estado externo deve ter um plano reverso claro.
- Acoplamento temporal: depender de respostas síncronas longas. Prefira comandos assíncronos e eventos.
- Falta de idempotência: causa efeitos duplicados e compensações em cascata.
- Orquestrador gordo: encher o orquestrador com regras complexas. Empurre decisões para DMN.
- Logs sem correlação: impossível auditar e depurar.
Exemplo de eventos (pseudo-JSON)
Comandos (do orquestrador para serviços):
{
"command": "ReserveStock",
"sagaId": "SAGA-2025-000123",
"orderId": "ORD-98765",
"items": [
{ "sku": "ABC-001", "qty": 2 }
],
"operationId": "op-1"
}
Eventos (dos serviços para o orquestrador):
{
"event": "StockReserved",
"sagaId": "SAGA-2025-000123",
"orderId": "ORD-98765",
"reservationId": "RSV-333",
"operationId": "op-1"
}
Compensação:
{
"command": "ReleaseStock",
"sagaId": "SAGA-2025-000123",
"reservationId": "RSV-333",
"reason": "PaymentFailed",
"operationId": "op-1c"
}
Repare na operationId para idempotência e na sagaId para rastreio ponta-a-ponta.
Como desenhar compensações eficazes
- Reversibilidade real: confirme que o sistema externo suporta desfazer (ex.: estorno, cancelamento, reabertura). Se não suportar, desenhe compensações semânticas (ex.: nota de crédito).
- Ordem inversa: aplique compensações na ordem inversa das ações (LIFO). Se reservou stock, debitou pagamento e criou fatura, a compensação começa por anular fatura, depois estornar pagamento, por fim libertar stock.
- Janelas e prazos: algumas compensações têm janelas (ex.: estorno até 7 dias). Modele exceções com DMN e BPMN (ramo manual).
- Efeitos colaterais: compensar pode gerar novos eventos (ex.: reabastecimento de stock). Garanta que o fluxo considera estes efeitos.
Papel do CMMN (quando “processo” não é linha reta)
Nem tudo é um fluxo determinístico. CMMN (Case Management Model and Notation) é útil quando:
- Existem tarefas ad-hoc ou investigação humana.
- Compensações dependem de avaliação contextual (fraude, compliance).
- O caso pode permanecer aberto com milestones e sentries a aguardar sinais (ex.: confirmação de parceiro).
Integração prática: o BPMN orquestra a saga “feliz” e os principais caminhos de compensação; um case CMMN é aberto quando surgem exceções complexas (disputa de pagamento, chargeback), permitindo intervenção humana com regras e SLAs próprios.
Observabilidade e governança
- Tracing distribuído (ex.: W3C TraceContext): propague
traceparentem todos os eventos. - Dashboards por etapa: quantas sagas em cada estado? Onde mais compensamos? Quais erros dominantes?
- Catálogo de eventos: versionamento, proprietários, semântica, exemplos.
- Políticas de retenção: eventos em quente (30–90 dias) e arquivo frio para auditoria.
- Segurança e conformidade: PII mascarada nos eventos; controlo de acesso ao log.
Checklist de boas práticas
- ✔︎ Cada passo com compensação explícita e testada.
- ✔︎ Estado da saga centralizado, com Correlation ID.
- ✔︎ Idempotência garantida para comandos e eventos.
- ✔︎ DMN para decisões de retry, escalada e ramos de compensação.
- ✔︎ SLAs/Timeouts modelados (timer boundary) e monitorizados.
- ✔︎ Outbox pattern e DLQ com reprocessamento seguro.
- ✔︎ Tracing distribuído e métricas de negócio.
- ✔︎ Testes de falha e chaos engineering periódicos.
- ✔︎ Documentação de riscos e janelas de compensação.
Conclusão
Orquestração por eventos não tem de ser caótica — quando há compensações, há tranquilidade. Sagas bem desenhadas substituem a fragilidade de um “rollback global” por uma abordagem semântica e resiliente, onde cada serviço faz a sua parte, e o todo permanece consistente. Modelando o fluxo em BPMN, externalizando regras em DMN e, quando necessário, envolvendo CMMN para exceções humanas, criamos sistemas que escalam, resistem a falhas e são auditáveis. O segredo está na disciplina: compensações explícitas, estado rastreável, idempotência, SLAs claros e observabilidade de ponta a ponta. Com estes pilares, a sua arquitetura event-driven ganha previsibilidade — e o seu negócio, paz de espírito.
You may also like


Leave a Reply